직렬과 병렬
병렬화
- 분담할 수 있는 처리는 cpu코어를 늘리면 빨라짐
- 처리시간을 1/N으로 감소
- 하지만 무조건 좋은건 아님 → 효과가 있을 때 병렬화 한다.
직렬화
- 분담할 수 없는 처리는 cpu코어를 늘려도 빨라지지 않음
- 처리시간 변화가 없음
- 쿨럭 주파수를 올리면 속도 향상
- 하지만 하드웨어를 어느정도 좋게 할 수 있지만 무한히 늘릴수는 없음( 하드웨어적 한계)
이것이 어디에 사용되나?
웹 서버와 AP서버에서
웹서버(아파치) - 복수의 프로세스가 분담해서 처리
AP서버 - 하나의 프로세스와 복수의 쓰레드로 처리
하지만
만약 CPU코어가 하나만 있다면 1개의 프로세스만 수행 가능
아파치 프로세스를 아무리 늘릴려고 해도 1개씩밖에 수행 못함
→ CPU코어수도 고려해야한다
DB서버에서
클라이언트 요청 접수 수만큼 프로세스 생성
공유 서버형이라 불리는 하이브리드 형도 있음
MYSQL에서 show processlist; (스레드인가?)
too many connection
| 장점 | 단점 | |
| 직렬 | 구조 간단 | 복수의 리소스 X |
| 병렬 | 복수의 리소스 O, 일부 고장나더라도 계속 처리 | 처리 분기나 합류를 위한 오버헤드 발생, 구조가 복잡, 합류점, 직렬화 구간, 분기점이 병목 지점이 되기 쉽다. |
그리고 병렬처리는 이중화라는 관점에서 장점이 있다.
동기 비동기
동기 - 어떠한 일이 끝날 때까지 기다림
비동기 - 어떠한 일을 다른누군가에 맡기고 다른일을 하고 있음
이것이 어디에 사용되나?
Ajax(synchronous Javascript And Xml) - 비동기 통신
브라우저가 가지고있는 XMLHttpRequest 객체를 이용해서 전체 페이지를 새로 고치지 않고도 페이지의 일부만을 위한 데이터를 로드하는 기법
웹 페이지가 로드된 후에 서버로 요청을 보내고
웹 페이지가 로드된 후에 서버로부터 응답을 받고
만약 이게 동기라면?
서버로 부터 요청 보내고 요청 받고 페이지 그려주고 반복..
DBMS에서 사용되는 비동기 I /O
HDD등의 저장소에 비동기로 쓰기 처리를 할 수 있다.
메모리에 있는 다수의 데이터를ㄹ 프로세스가 HDD에 기록하는 경우 사용
동기 I/O 방식을 병렬화 하려면 DBMS 프로세스를 늘리면됨
비동기I/O 방식은 비동기로 I/O에 요구한 후에 I/O가 끝났는지 여부를 확인
| 장점 | 단점 | |
| 동기 | 구조 간단, 구현 난이도 낮음 | 대기시간을 활용 못함 |
| 비동기 | 시간을 효율적으로 사용해서 병렬 처리를 할 수 있음 | 의뢰한 처리가 끝났는지 확인하는 등의 불필요한 처리가 늘어남, 구조 복잡 |
큐
- 선입선출 (First In First Out)
이것이 어디에 사용되나?
- cpu처리를 기다리고 있는 프로세스나 스레드
- 저장소 읽기 처리를 기다리는 I/O
- 네트워크 접속 성립을 기다리고 있는 접속 요구
데이터베이스 큐, OS런큐, I/O 요청 큐 등을 확인하면 처리 지연이 발생하고 있는지 확인 가능
복수의 처리가 동시에 진행되는 부분에서는 큐를 많이 사용해서 성능 문제 발생 → cpu사용률, 런큐 길이 확인
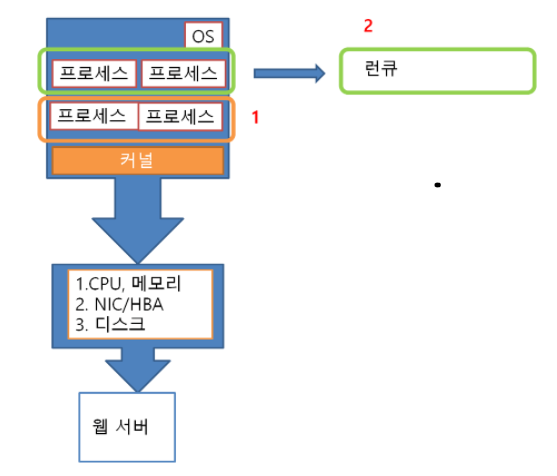
런큐에 쌓인 프로세스 수를 코어 수로 나누어서 1이라면 문제 없음
런큐 - 프로세스 행렬
메세지 큐
Application, 시스템, 서비스들 연결해주는 솔루션
데이터 처리를 하다보면 성능이 낮아짐

producer가 queue에 넣어두면 consumer이 queue에 있는 것을 가져와서 처리
→ 중간에 큐를 하나 둬서 순차적으로 처리하게끔 처리를 합니다 (pub/sub)
배타적 제어
- 여러 사람이 공유하는 물건일 경우 그 물건을 사용하고 있으면 다른 사람은 그것을 사용 못함
- 병렬처리에서 사용
- 복수의 처리가 공유자원에 동시에 액세스하면 불일치 발생할 수 있어서 배타적 제어로 보호
- 병목현상 발생
이것이 어디에 사용되나?
DBMS
공유 데이터를 변경하고 있는 도중에 다른 프로세스가 데이터를 읽거나 공유 데이터를 동시에 변경하지 못하게 함 - rock syncronize
스핀락 - cpu에서 의미없는 처리를 하면서 대기
슬립락 - 장시간 락을 유지하도록 큐를 이용해서 관리하는 방식
os커널
빅 커널락(BKL) - 빅 커널락이 이용되는 부분에서는 처리가 직렬화가 돼서 하나의 cpu만 커널 코드를 실행 (병목지점이 될 수 있다. 병렬화 → 직렬화)

| 장점 | 단점 | |
| 배타적 제어 사용 | 공유 데이터 일관성 유지 | 병렬 처리 X |
| 배타적 제어 사용 X | 병렬처리 | 데이터 불일치 가능성이 있음 |
정말 필요한 곳에만 해야 효율적
상태 저장 / 상태 비저장
- 상태 저장 - 상태 정보를 가지고 있음 (ssh) , 복잡한 처리가 가능(과거 정보를 가지고 올 수 있음) , 시스템 복잡성 커짐
- 상태 비저장 - 상태 정보를 가지고 있지 않음 (http), 상태를 고려하지 않기 때문에 간단, 성능이나 안정성이 좋음
이것이 어디에 사용되나?
컴퓨터 내부 구조
프로세스의 상태들
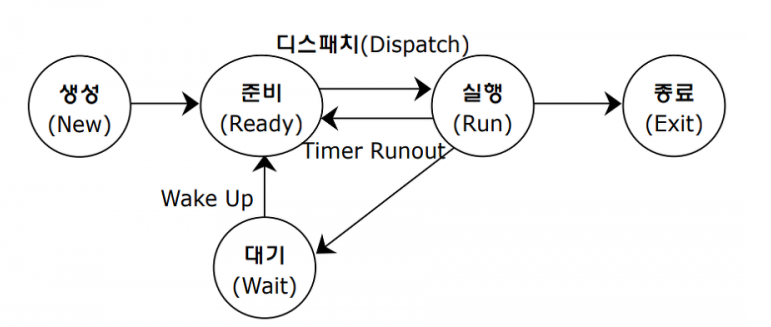
네트워크 통신
상태가 없기 때문에 같은 요청을 보내면 같은 데이터 반환
쇼핑사이트 - 회원전용 페이지를 보여주고 싶지만 상태가 없어서 회원인지 모름
기본적으로 상태 비저장 방식이지만 한번 로그인 하고 이후에는 계속 그 인증 정보를 유지하는 방식 사용
가변 길이/ 고정 길이
고정길이 - 크기가 정해져 있음 , 쓸데없는 공간 생김, 성능면에서 좋음(종류별로 나뉘어져 있으면 바로 찾기 가능)
가변 길이 - 정해져 있지 않음, 공간을 유용하게 활용, 성능면에서 불안
이것이 어디에 사용되나?
파일 시스템
파일 시스템에서는 각종 파일을 고정 길이로 저장
네트워크 데이터 교환

데이터 구조(배열과 연결 리스트)
데이터를 순차적으로 처리하지만 구조가 다름
배열 - 데이터를 빈틈없이 순서대로 나열
연결 리스트 - 데이터를 선으로 연결한 데이터구조
성능은 다들 아시죠?
이 두 데이터의 하이브리등형 데이터가 해시 테이블이다.
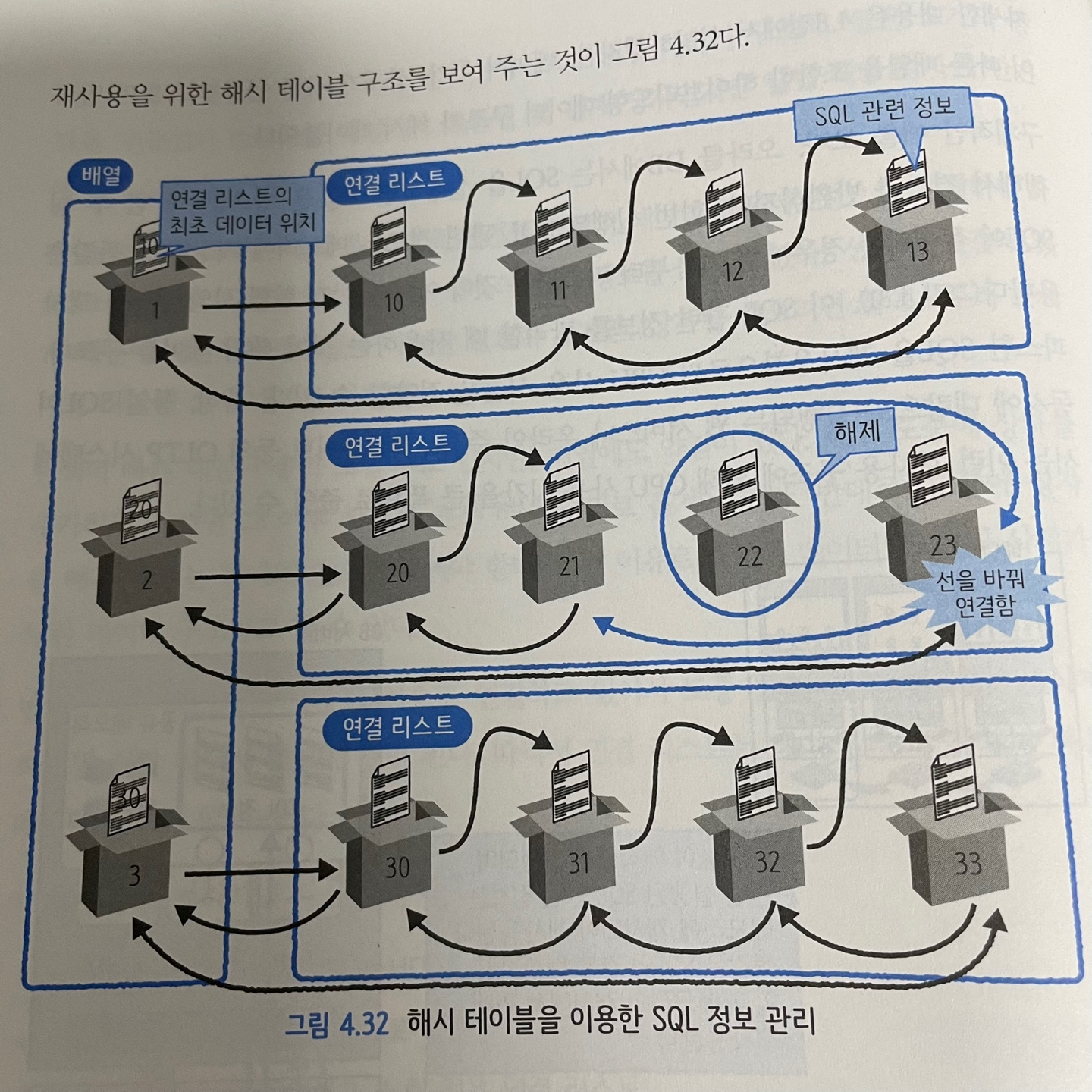
처음 실행된 sql문은 메모리에 남음.
하지만 sql문은 산재하고 있기 때문에 추가, 삭제가 빠른 연결리스트를 사용하면 해제 처리가 빠름
하지만 탐색이 느리다.
하지만 sql은 길이가 제각각이셔서 관리 불가능. 해시 함수를 이용해서 sql을 고정길이 해시값으로 변환해서 배열로 저장. → 빠르게 탐색 가능
탐색 알고리즘
해시나 트리가 데이터 구조지만 효율적 탐색을 위해 사용
- 필요할 때 데이터를 찾기위해 데이터를 정리
- 데이터 저장 방식과 특성에 따라 데이터 저장 방법이 달라짐
이것이 어디에 사용되나?
DB인덱스
만약 인덱스가 없다면 데이터를 모두 읽어야함
인덱스가 있으면 필요한 부분만 읽음 → 검색 속도가 빨라짐
단점 - 데이터 추가, 갱신, 삭제 시 인덱스 데이터도 갱신 → 오버헤드가 발생 할 수 있음
인덱스의 구조
B트리 인덱스
해시 테이블
- 키와 값 조합으로 표를 구성한 데이터 구성
- 키는 해시 함수를 통해 해시 값으로 변환 → 고정길이 데이터 → 구조가 간단, 검색이 빠름
'책 > 그림으로 공부하는 IT인프라 구조' 카테고리의 다른 글
| 무정지를 위한 인프라 구조(2) (0) | 2021.10.10 |
|---|---|
| 무정지를 위한 인프라 구조(1) (0) | 2021.10.08 |
| 시스템을 연결하는 네트워크 구조 (0) | 2021.10.07 |
| 3계층형 시스템 (0) | 2021.09.27 |
| 인프라 아키텍처!! (0) | 2021.09.25 |