책/real mysql
5. 인덱스(2) - 그외 인덱스
ballde
2021. 12. 30. 18:26
이전글에서 이어진 글입니다
https://balldev.tistory.com/59
5장. 인덱스
디스크 읽기 방식 데이터베이스의 성능 튜닝은 어떻게 디스크 I/O를 줄이느냐가 관건인 것들이 상당함 저장 매체 DAS 컴퓨터의 본체와 달리 디스크만 있음 모두 SATA SAS와 같은 케이블로 연결되어
balldev.tistory.com
해시 인덱스
- 해시 인덱스는 동등 비교 검색에는 최적화 but 범위를 검색한다거나 정렬된 결과를 가져오는 목적으로는 사용할 수 없다.
- DBMS에서 메모리 기반의 테이블에 주로 구현 → 대용량 테이블용으로는 사용 X
구조 및 특성
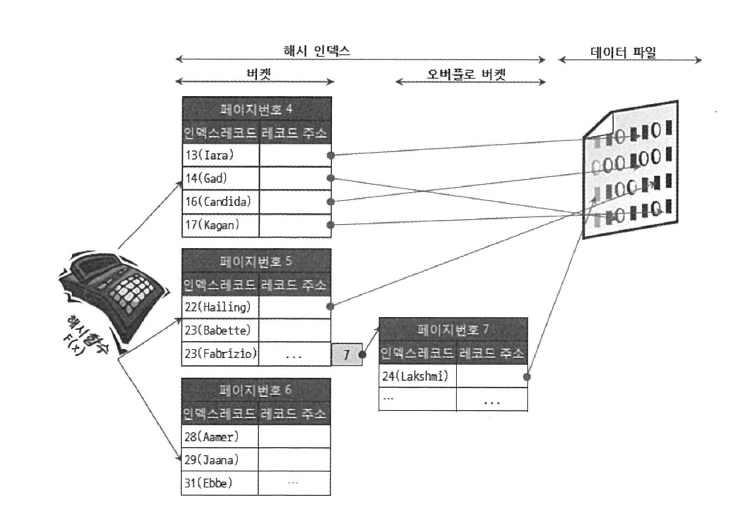
- 실제 키 값과는 상관 없이 인덱스 크기가 작고 검색이 빠름
- 검색하고자 하는 값을 주면 해시함수를 거쳐서 키 값이 포함된 버켓을 알 수 있음. 그리고 하나만 읽어서 비교해 보면 실제 레코드가 저장된 위치를 알 수 있음
클러스터링 인덱스
- MySQL에서 InnoDB, TokuDB 스토리 엔진에서만 클러스터링 인덱스를 지원
- PK 키값이 비슷한 레코드끼리 묶어서 저장하는 것
- 일반적으로 InnoDB와 같이 항상 클러스터링 인덱스로 저장되는 테이블은 PK 기반의 검색이 매우 빠름
- 대신 레코드의 저장이나 프라이머리 키의 변경이 상대적으로 느림
- 그러므로 가능하다면 PK를 명시
보조 인덱스에 미치는 영향
- InnoDB 테이블의 모든 보조 인덱스는 해당 레코드가 저장된 주소가 아니라 PK 키값을 저장하도록 구현
- 보조 인덱스를 검색해 레코드의 PK 키 값을 확인 ⇒ PK 키값을 이용해서 최종 레코드를 가져옴.
클러스터링 인덱스의 장/단점
장점
- PK로 검색할 때 처리 성능이 매우 빠름
- 테이블의 모든 보조 인덱스가 PK를 가지고 있기 때문에 인덱스만으로 처리될 수 있는 경우가 많음 (커버링인덱스)
단점
- 테이블의 모든 보조 인덱스가 클러스터 키를 갖기 때문에 클러스터 키 값의 크기가 클 경우 전체적으로 인덱스의 크기가 커짐
- 보조 인덱스를 통해 검색할 때 PK 키로 다시 한번 검색해야 하므로 처리 성능이 조금 느림
- INSERT할 때 PK에 의해 레코드의 저장 위치가 결정되기 때문에 처리 성능이 느림
- PK를 변경할 때 레코드를 DELETE 하고 INSERT 하는 작업이 필요해서 처리 성능이 느림
유니크 인덱스
- 말 그대로 테이블이나 인덱스에 같은 값이 2개 이상 저장될 수 없음을 의미하는데, MySQL에서는 인덱스 없이 유니크 제약만 설정할 방법이 없습니다. 유니크 인덱스에서 NULL도 저장될 수 있는데, NULL은 특정의 값이 아니므로 2개 이상 저장될 수 있습니다.
유니크 인덱스 - 보조 인덱스
- MySQL에서는 유니크 인덱스에 중복된 값을 체크할 때는 읽기 잠금을 사용
- 쓰기를 할 때는 쓰기 잠금을 사용하는데, 이 과정에서 데드락이 아주 빈번히 발생한다.
- InnoDB 스토리지 엔진에서는 인덱스의 키의 저장을 버퍼링 하기 위해 인서트 버퍼가 사용된다. 그래서 인덱스의 저장이나 변경 작업이 상당히 빨리 처리되지만, 유니크 인덱스는 반드시 중복 체크를 해야 하므로 작업 자체를 버퍼링 하지 못한다. (이 때문에 유니크 인덱스는 일반 보조 인덱스보다 더 느려진다)
유니크의 주의사항
- MySQL의 유니크 인덱스는 일반 다른 인덱스와 같은 역할을 하므로 중복해서 인덱스를 생성할 필요 없다.
- 유일성이 꼭 보장돼야 하는 컬럼에서는 유니크 인덱스를 생성하되, 꼭 필요하지 않다면 유니크 인덱스보다는 유니크하지 않은 보조 인덱스를 생성하는 방법도 한 번씩 고려해보자.